与上一篇介绍的 KafkaProducer 一样,Kafka 消费者 KafkaConsumer 同样是 Kafka 与开发者交互的媒介之一,负责从 Kafka 集群拉取消息给应用程序消费,并提交已经消费完成的 offset 值。此外,考虑到消费者上下线、topic 分区数目变更等情况,KafkaConsumer 还需要负责与服务端交互执行分区再分配操作,以保证消费者能够更加均衡的消费 topic 分区,从而提升消费的性能。
Kafka 定义了 group 的概念,将多个消费者实例组织成为一个 group,以丰富 Kafka 的应用场景。一个 group 名下可以包含任意数量的消费者实例,并从这些消费者中选择一个消费者担任 group 中的 Leader 消费者角色,负责管理 group 和其它 Follower 角色消费者的状态。当有消费者加入或离开当前 group 时,Group Leader 会依据集群确定的分区分配策略,为 group 名下所有消费者重新分配分区,以保证消息消费的均衡性。
本文我们同样先回忆一下 KafkaConsumer 的使用方式,然后重点分析消息的拉取过程、分区再分配机制,以及 offset 提交机制。
我们仍然以 Kafka 内置的 java 客户端为例,介绍如何消费 Kafka 中的消息。示例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 Properties properties = new Properties(); properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092" ); properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, IntegerDeserializer.class.getName()); properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); properties.put(ConsumerConfig.GROUP_ID_CONFIG, DEFAULT_GROUP); properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false" ); KafkaConsumer<Integer, String> consumer = new KafkaConsumer<>(properties); consumer.subscribe(Collections.singleton(DEFAULT_TOPIC)); while (!Thread.currentThread().isInterrupted()) { ConsumerRecords<Integer, String> records = consumer.poll(TimeUnit.SECONDS.toMillis(1 )); try { for (final ConsumerRecord<Integer, String> record : records) { this .printResult(record); } consumer.commitAsync(); } catch (Throwable e) { } finally { consumer.commitSync(); } }
示例中消费消息依赖于 KafkaConsumer 对象,KafkaConsumer 类也是我们分析消费者运行机制的入口。创建 KafkaConsumer 类对象时我们需要指定 Kafka 集群地址,以及消息 key 和 value 的反序列化器。接着我们可以循环调用 KafkaConsumer#poll 方法从 Kafka 集群拉取消息进行消费,该方法接收一个 timeout 参数,用于设置等待消息返回的超时时间,如果设置为 0 则 Kafka 会立即从本地缓存的消息集合中获取符合期望的结果进行返回。
读者可能对 timeout=0 的设置有些疑惑,认为这样的参数设置意义不大,因为一次网络请求多少都有时间上开销,这样的理解也是没有错的。但是后面在分析消息的消费过程时你将会看到,实际从集群拉取当前请求的消息的过程并不是在调用 poll 方法之后完成的。Kafka 为了性能考虑,在返回消息之前已经发送了下一次拉取消息的请求,这样处理消息的过程与请求下一轮消息的过程就是并行执行的。如果网络足够快,或者处理消息的逻辑足够耗时,则设置 timeout=0 是完全能够平滑工作的。
示例中我们关闭了 offset 的自动提交策略,并在正常运行过程中启用异步提交来提升性能,只有当出现异常的情况下才会使用同步提交,以防止 offset 丢失。
我们以 KafkaConsumer 类为入口开始分析消费者的运行机制,首先来看一下 KafkaConsumer 类的字段定义:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 public class KafkaConsumer <K , V > implements Consumer <K , V > private static final AtomicInteger CONSUMER_CLIENT_ID_SEQUENCE = new AtomicInteger(1 ); private final String clientId; private final ConsumerCoordinator coordinator; private final Deserializer<K> keyDeserializer; private final Deserializer<V> valueDeserializer; private final Fetcher<K, V> fetcher; private final ConsumerInterceptors<K, V> interceptors; private final Time time; private final ConsumerNetworkClient client; private final SubscriptionState subscriptions; private final Metadata metadata; private final long retryBackoffMs; private final long requestTimeoutMs; private volatile boolean closed = false ; private final AtomicLong currentThread = new AtomicLong(NO_CURRENT_THREAD); private final AtomicInteger refcount = new AtomicInteger(0 ); }
KafkaConsumer 对象的构造的过程比较简单,这里不再展开。
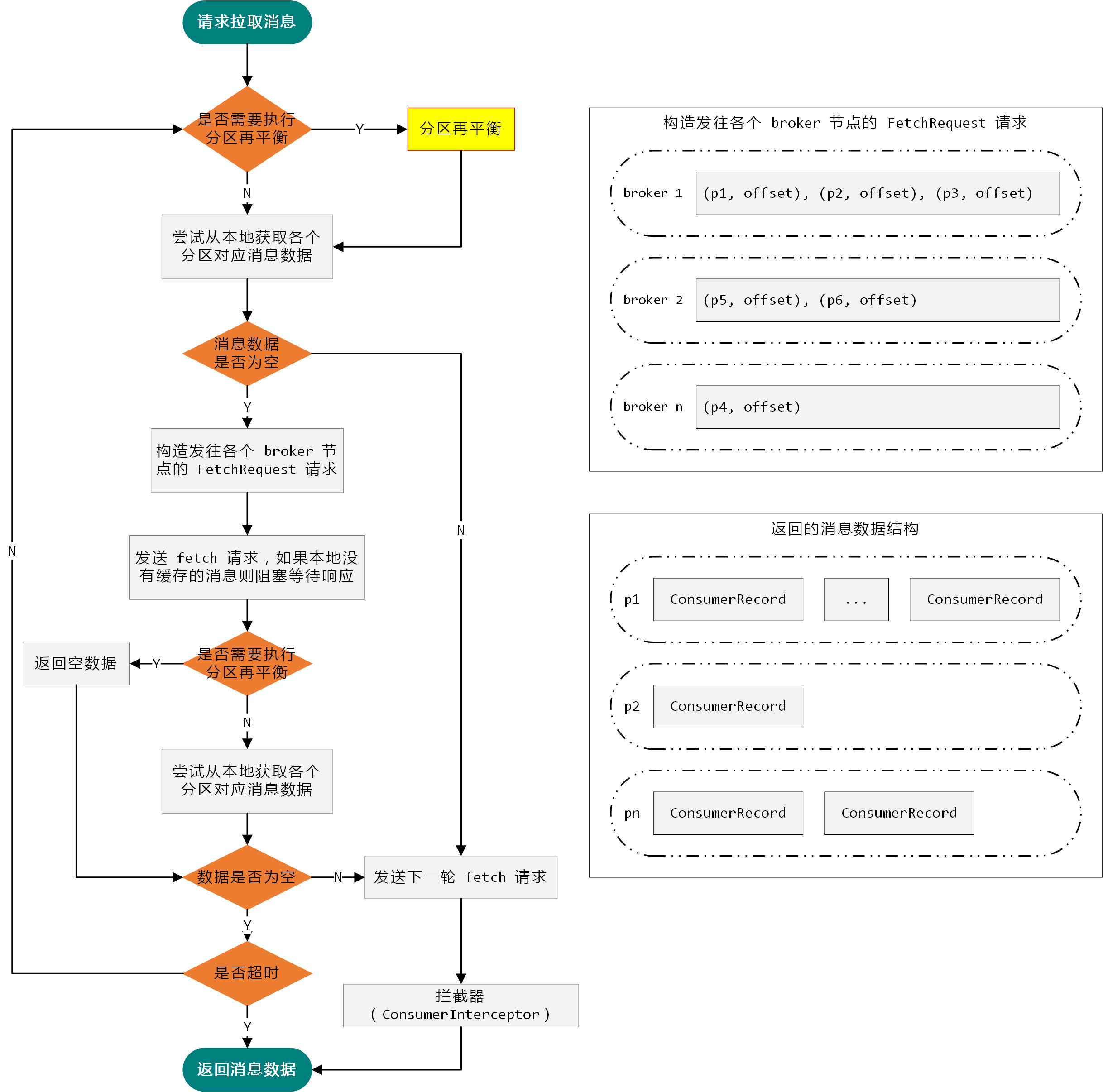
与介绍 KafkaProducer 一样,在深入分析 KafkaConsumer 的运行机制之前,我们同样以一张图(如上图)从整体层面对消费消息的过程做一个整体的介绍。
当消费者请求拉取消息消费时,KafkaConsumer 会首先检查当前是否需要执行分区再平衡操作。Kafka 限定一个分区至多只能被一个消费者消费,因为消费者可能会发生上下线操作,并且分区的数量也可能会增加,所以 Kafka 内置了分区再平衡机制,尽量保证将分区均匀分配给各个消费者。
此外,为了提升消费的性能,Kafka 巧妙的将处理消息的过程与拉取消息的过程并行化。KafkaConsumer 在将消息返回给应用程序之前会发送拉取后续消息的请求,这样能够实现应用程序在处理消息的时候,KafkaConsumer 也在后台为应用程序准备下一轮需要消费的消息。所以,应用程序大多数时候都是直接从本地获取到缓存的消息数据,期间无需等待与 Kafka 集群的远程通信。
上述是整个消费者运行机制的两个关键点,下面的小节我们将展开对整个消费者运行机制进行深入分析。
在使用 KafkaConsumer 消费服务端消息之前,我们首先需要调用 KafkaConsumer#subscribe 方法订阅 topic 列表,该方法实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public void subscribe (Collection<String> topics, ConsumerRebalanceListener listener) this .acquire(); try { if (topics == null ) { throw new IllegalArgumentException("Topic collection to subscribe to cannot be null" ); } else if (topics.isEmpty()) { this .unsubscribe(); } else { subscriptions.subscribe(new HashSet<>(topics), listener); metadata.setTopics(subscriptions.groupSubscription()); } } finally { this .release(); } }
在开始订阅 topic 之前会先校验 KafkaConsumer 对象是否被多个线程占用。我们知道 KafkaConsumer 不是线程安全的,KafkaConsumer 设置了两个字段 KafkaConsumer#currentThread 和 KafkaConsumer#refcount 用于控制访问当前 KafkaConsumer 对象的线程 ID 和线程重入次数。其中 currentThread 用于记录持有当前 KafkaConsumer 对象的线程 ID,refcount 则表示该线程的重入次数。对于这 2 个变量的控制,KafkaConsumer 一般会使用下面这样的模板代码:
1 2 3 4 5 6 this .acquire();try { } finally { this .release(); }
其中 KafkaConsumer#acquire 方法可以类比理解为加锁,而 KafkaConsumer#release 方法可以类比理解为释放锁。我们先来看一下 KafkaConsumer#acquire 方法,该方法首先会验证当前 KafkaConsumer 对象是否被关闭,如果没有被关闭则会继续验证当前操作线程是否是已经持有该 KafkaConsumer 对象的线程,如果不是且当前 KafkaConsumer 对象被其它线程持有,则会抛出异常,否则将重入计数 refcount 加 1。以此来保证一个 KafkaConsumer 对象在同一时段只能被同一个线程持有,但是允许同一个线程多次持有。方法 KafkaConsumer#acquire 实现如下:
1 2 3 4 5 6 7 8 9 10 11 private void acquire () this .ensureNotClosed(); long threadId = Thread.currentThread().getId(); if (threadId != currentThread.get() && !currentThread.compareAndSet(NO_CURRENT_THREAD, threadId)) { throw new ConcurrentModificationException("KafkaConsumer is not safe for multi-threaded access" ); } refcount.incrementAndGet(); }
再来看一下 KafkaConsumer#release 方法的实现(如下),该方法逻辑比较简单,将重入计数 refcount 减 1,意味着本次线程退出当前临界区,如果重入计数为 0,则清空 currentThread,以允许其它线程获取锁。
1 2 3 4 5 6 7 private void release () if (refcount.decrementAndGet() == 0 ) { currentThread.set(NO_CURRENT_THREAD); } }
在保证线程安全的前提下,方法 KafkaConsumer#subscribe 会对传递的 topic 集合进行校验,如果当前传递的 topic 集合为空,则视为取消订阅。取消订阅主要做了 2 件事情:
清空本地订阅的 topic 集合、清除本地记录的每个 topic 分区的消费状态,以及重置一些本地的变量。
构建并发送 LeaveGroupRequest 请求,告知服务端自己已经离开当前的 group。
如果传递的 topic 集合不为空,则会调用 SubscriptionState#subscribe 方法订阅指定 topic 集合,实现如下:
1 2 3 4 5 6 7 8 9 10 public void subscribe (Set<String> topics, ConsumerRebalanceListener listener) if (listener == null ) { throw new IllegalArgumentException("RebalanceListener cannot be null" ); } this .setSubscriptionType(SubscriptionType.AUTO_TOPICS); this .listener = listener; this .changeSubscription(topics); }
同一个 KafkaConsumer 对象订阅主题的模式有 3 种,定义在 SubscriptionType 枚举类中(其中 NONE 指代未订阅任何主题):
1 2 3 4 5 6 7 8 9 private enum SubscriptionType NONE, AUTO_TOPICS, AUTO_PATTERN, USER_ASSIGNED }
并且这些订阅模式之间是互斥的,即一个 KafkaConsumer 对象不允许同时使用多种模式进行订阅,相关控制位于 SubscriptionState#setSubscriptionType 方法中:
1 2 3 4 5 6 7 8 9 private void setSubscriptionType (SubscriptionType type) if (this .subscriptionType == SubscriptionType.NONE) { this .subscriptionType = type; } else if (this .subscriptionType != type) { throw new IllegalStateException(SUBSCRIPTION_EXCEPTION_MESSAGE); } }
如果当前的订阅模式合法,则会继续调用 SubscriptionState#changeSubscription 方法依据本次订阅的 topic 集合更新 SubscriptionState#subscription 和 SubscriptionState#groupSubscription 字段。其中 subscription 字段用于记录当前消费者订阅的 topic 集合,而 groupSubscription 字段则依据当前消费者是 Leader 还是 Follower 有所不同。如果是 Leader 则记录当前消费者所属 group 中所有消费者订阅的 topic 集合,如果是 Follower 则仅保存其自身订阅的 topic 集合。到这里,订阅 topic 的过程就算完成了,整个过程还未涉及到与集群的交互,这会在执行 KafkaConsumer#poll 时发生。
在完成了对目标 topic 的订阅之后,下面继续分析从集群拉取消息的过程,位于 KafkaConsumer#poll 方法中,实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 public ConsumerRecords<K, V> poll (long timeout) this .acquire(); try { if (timeout < 0 ) { throw new IllegalArgumentException("Timeout must not be negative" ); } if (subscriptions.hasNoSubscriptionOrUserAssignment()) { throw new IllegalStateException("Consumer is not subscribed to any topics or assigned any partitions" ); } long start = time.milliseconds(); long remaining = timeout; do { Map<TopicPartition, List<ConsumerRecord<K, V>>> records = this .pollOnce(remaining); if (!records.isEmpty()) { if (fetcher.sendFetches() > 0 || client.pendingRequestCount() > 0 ) { client.pollNoWakeup(); } if (this .interceptors == null ) { return new ConsumerRecords<>(records); } else { return this .interceptors.onConsume(new ConsumerRecords<>(records)); } } long elapsed = time.milliseconds() - start; remaining = timeout - elapsed; } while (remaining > 0 ); return ConsumerRecords.empty(); } finally { this .release(); } }
上述方法返回一个 ConsumerRecords 对象,用于对从每个 topic 分区拉取回来的 ConsumerRecord 对象集合进行封装。前面我们在分析 KafkaProducer 时介绍了 ProducerRecord 类,用于封装 Producer 发送的每条消息,而 ConsumerRecord 类则与之对应,用于封装 Consumer 消费的每条消息。
从集群拉取消息时需要指定响应超时时间 timeout 参数,该参数允许设置为非负数,前面我们已经介绍了 timeout=0 的意义,相应的逻辑位于这里实现。方法首先会调用 KafkaConsumer#pollOnce 从本地或服务端拉取一批消息,如果拉取成功(即返回结果不为空),方法并不会立即将结果返回,而是在返回之前尝试发送下一次拉取消息的请求。因为拉取消息涉及网络通信,需要与远端集群进行交互,比较耗时,而业务处理消息也是一个耗时的过程,Kafka 的设计者巧妙的将这两步并行执行,以提升效率。
如果设置了 Consumer 拦截器,那么在返回待消费消息数据之前会先对消息执行拦截修改。Kafka 定义了 ConsumerInterceptor 接口,该接口定义如下:
1 2 3 4 5 public interface ConsumerInterceptor <K , V > extends Configurable ConsumerRecords<K, V> onConsume (ConsumerRecords<K, V> records) ; void onCommit (Map<TopicPartition, OffsetAndMetadata> offsets) void close () }
其中 ConsumerInterceptor#onConsume 方法会在消息数据被返回给应用程序之前执行,如 KafkaConsumer#poll 方法所示,而方法 ConsumerInterceptor#onCommit 会在 offset 成功提交后被调用。
下面先跳过 KafkaConsumer#pollOnce 方法来看一下 Fetcher#sendFetches 方法的实现,因为在 pollOnce 中同样调用了该方法,所以先了解其执行逻辑,以便于更好的理解 pollOnce 所做的工作。方法 Fetcher#sendFetches 的主要工作就是构建并向集群发送 FetchRequest 请求,以拉取指定 offset 的消息。Fetcher 类主要负责从服务端拉取消息,其字段定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 public class Fetcher <K , V > implements SubscriptionState .Listener private final ConsumerNetworkClient client; private final Time time; private final int minBytes; private final int maxBytes; private final int maxWaitMs; private final int fetchSize; private final long retryBackoffMs; private final int maxPollRecords; private final boolean checkCrcs; private final Metadata metadata; private final SubscriptionState subscriptions; private final ConcurrentLinkedQueue<CompletedFetch> completedFetches; private final Deserializer<K> keyDeserializer; private final Deserializer<V> valueDeserializer; private final BufferSupplier decompressionBufferSupplier = BufferSupplier.create(); private PartitionRecords<K, V> nextInLineRecords = null ; private ExceptionMetadata nextInLineExceptionMetadata = null ; }
下面来看一下 Fetcher#sendFetches 方法的实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 public int sendFetches () Map<Node, FetchRequest.Builder> fetchRequestMap = this .createFetchRequests(); for (Map.Entry<Node, FetchRequest.Builder> fetchEntry : fetchRequestMap.entrySet()) { final FetchRequest.Builder request = fetchEntry.getValue(); final Node fetchTarget = fetchEntry.getKey(); log.debug("Sending fetch for partitions {} to broker {}" , request.fetchData().keySet(), fetchTarget); client.send(fetchTarget, request) .addListener(new RequestFutureListener<ClientResponse>() { @Override public void onSuccess (ClientResponse resp) FetchResponse response = (FetchResponse) resp.responseBody(); if (!matchesRequestedPartitions(request, response)) { log.warn("Ignoring fetch response containing partitions {} since it does not match the requested partitions {}" , response.responseData().keySet(), request.fetchData().keySet()); return ; } Set<TopicPartition> partitions = new HashSet<>(response.responseData().keySet()); FetchResponseMetricAggregator metricAggregator = new FetchResponseMetricAggregator(sensors, partitions); for (Map.Entry<TopicPartition, FetchResponse.PartitionData> entry : response.responseData().entrySet()) { TopicPartition partition = entry.getKey(); long fetchOffset = request.fetchData().get(partition).offset; FetchResponse.PartitionData fetchData = entry.getValue(); completedFetches.add(new CompletedFetch(partition, fetchOffset, fetchData, metricAggregator, request.version())); } sensors.fetchLatency.record(resp.requestLatencyMs()); sensors.fetchThrottleTimeSensor.record(response.getThrottleTime()); } @Override public void onFailure (RuntimeException e) log.debug("Fetch request to {} for partitions {} failed" , fetchTarget, request.fetchData().keySet(), e); } }); } return fetchRequestMap.size(); }
上述方法的主要执行逻辑就是获取需要拉取消息的 topic 分区集合,并为每个分区创建对应的 FetchRequest 请求对象,同时将这些请求按照分区对应的 Leader 副本所在 broker 节点组成 Map<Node, FetchRequest.Builder> 集合。接着,方法会遍历处理该集合向对应节点发送 FetchRequest 请求,并注册 RequestFutureListener 监听器对响应结果进行处理。如果响应中的分区集合与请求时的分区集合能够匹配,则方法会遍历响应结果,并将每个分区 offset 对应的响应结果对象封装成 CompletedFetch 对象,记录到 Fetcher#completedFetches 同步队列中。CompletedFetch 仅仅是对响应的一个简单的封装,后面会消费该队列,并将获取到的 CompletedFetch 对象解析成 ConsumerRecord 对象封装到 PartitionRecords 中,该类记录了消息对应的分区、offset、消息集合,以及客户端消费的位置等信息。
消费逻辑由 Fetcher#fetchedRecords 方法实现,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 CompletedFetch completedFetch = completedFetches.poll(); if (completedFetch == null ) break ; try { nextInLineRecords = this .parseCompletedFetch(completedFetch); } catch (KafkaException e) { if (drained.isEmpty()) { throw e; } nextInLineExceptionMetadata = new ExceptionMetadata(completedFetch.partition, completedFetch.fetchedOffset, e); } private PartitionRecords<K, V> parseCompletedFetch (CompletedFetch completedFetch) TopicPartition tp = completedFetch.partition; FetchResponse.PartitionData partition = completedFetch.partitionData; long fetchOffset = completedFetch.fetchedOffset; int bytes = 0 ; int recordsCount = 0 ; PartitionRecords<K, V> parsedRecords = null ; Errors error = Errors.forCode(partition.errorCode); try { if (!subscriptions.isFetchable(tp)) { log.debug("Ignoring fetched records for partition {} since it is no longer fetchable" , tp); } else if (error == Errors.NONE) { Long position = subscriptions.position(tp); if (position == null || position != fetchOffset) { log.debug("Discarding stale fetch response for partition {} since its offset {} does not match the expected offset {}" , tp, fetchOffset, position); return null ; } List<ConsumerRecord<K, V>> parsed = new ArrayList<>(); boolean skippedRecords = false ; for (LogEntry logEntry : partition.records.deepEntries(decompressionBufferSupplier)) { if (logEntry.offset() >= position) { parsed.add(this .parseRecord(tp, logEntry)); bytes += logEntry.sizeInBytes(); } else { skippedRecords = true ; } } recordsCount = parsed.size(); log.trace("Adding fetched record for partition {} with offset {} to buffered record list" , tp, position); parsedRecords = new PartitionRecords<>(fetchOffset, tp, parsed); if (partition.highWatermark >= 0 ) { log.trace("Received {} records in fetch response for partition {} with offset {}" , parsed.size(), tp, position); subscriptions.updateHighWatermark(tp, partition.highWatermark); } } } finally { completedFetch.metricAggregator.record(tp, bytes, recordsCount); } if (bytes > 0 || error != Errors.NONE) { subscriptions.movePartitionToEnd(tp); } return parsedRecords; }
从队列中获取到的 CompletedFetch 对象会调用 Fetcher#parseCompletedFetch 方法将其解析封装成 PartitionRecords 对象,并记录到 Fetcher#nextInLineRecords 字段中,等待后续处理。下面来完整看一下 Fetcher#fetchedRecords 方法的实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 public Map<TopicPartition, List<ConsumerRecord<K, V>>> fetchedRecords() { if (nextInLineExceptionMetadata != null ) { ExceptionMetadata exceptionMetadata = nextInLineExceptionMetadata; nextInLineExceptionMetadata = null ; TopicPartition tp = exceptionMetadata.partition; if (subscriptions.isFetchable(tp) && subscriptions.position(tp) == exceptionMetadata.fetchedOffset) { throw exceptionMetadata.exception; } } Map<TopicPartition, List<ConsumerRecord<K, V>>> drained = new HashMap<>(); int recordsRemaining = maxPollRecords; while (recordsRemaining > 0 ) { if (nextInLineRecords == null || nextInLineRecords.isDrained()) { } else { TopicPartition partition = nextInLineRecords.partition; List<ConsumerRecord<K, V>> records = this .drainRecords(nextInLineRecords, recordsRemaining); if (!records.isEmpty()) { List<ConsumerRecord<K, V>> currentRecords = drained.get(partition); if (currentRecords == null ) { drained.put(partition, records); } else { List<ConsumerRecord<K, V>> newRecords = new ArrayList<>(records.size() + currentRecords.size()); newRecords.addAll(currentRecords); newRecords.addAll(records); drained.put(partition, newRecords); } recordsRemaining -= records.size(); } } } return drained; }
前面我们在分析消费 Fetcher#completedFetches 同步队列时,对于解析过程中出现异常的 topic 分区对应的 offset,会将异常信息封装成 ExceptionMetadata 对象,记录到 Fetcher#nextInLineExceptionMetadata 字段中,方法 Fetcher#fetchedRecords 一开始会先处理该异常。如果之前解析过程能够正常拿到消息并封装成 PartitionRecords 对象,那么接下来将会从对象中拉取指定数量的消息返回给用户。该过程位于 Fetcher#drainRecords 方法中,该方法会校验目标分区是否被分配给当前消费者,因为在执行分区再分配时,一个消费者消费的分区是可能变化的,我们将在后面对分区再分配的逻辑进行针对性分析。如果目标 topic 分区仍然是分配给当前消费者的,那么方法会在对应分区允许拉取消息的情况下,从之前解析得到的 PartitionRecords 中获取指定数量的消息,并更新客户端记录的位置信息,包括对应分区的 offset,以及 PartitionRecords 中缓存的消息集合的消费位置。最后将每个分区对应的消息集合封装成 Map<TopicPartition, List<ConsumerRecord<K, V>>> 集合返回。
下面我们回到 KafkaConsumer 类,看一下 KafkaConsumer#pollOnce 方法的执行逻辑,了解了 Fetcher#sendFetches 和 Fetcher#fetchedRecords 的实现,再来看 pollOnce 方法会简单很多。该方法实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 private Map<TopicPartition, List<ConsumerRecord<K, V>>> pollOnce(long timeout) { coordinator.poll(time.milliseconds()); if (!subscriptions.hasAllFetchPositions()) { this .updateFetchPositions(subscriptions.missingFetchPositions()); } Map<TopicPartition, List<ConsumerRecord<K, V>>> records = fetcher.fetchedRecords(); if (!records.isEmpty()) { return records; } fetcher.sendFetches(); long now = time.milliseconds(); long pollTimeout = Math.min(coordinator.timeToNextPoll(now), timeout); client.poll(pollTimeout, now, new PollCondition() { @Override public boolean shouldBlock () return !fetcher.hasCompletedFetches(); } }); if (coordinator.needRejoin()) { return Collections.emptyMap(); } return fetcher.fetchedRecords(); }
在拉取消息之前会先尝试执行分区再分配策略,以及异步提交 offset,这 2 步我们先不展开,留到后面的小节中针对性分析。
由于 Kafka 在设计上由消费者自己维护自身消费状态,所以在拉取消息之前需要确定是否需要更新消费者维护的分区 offset 信息,一方面是为了支持分区重置策略,另一方面也是配合分区再分配操作。KafkaConsumer 在拉取消息数据之前会调用 SubscriptionState#hasAllFetchPositions 方法检测分配给当前消费者的分区在本地是不是都记录着对应的 offset 值,如果存在没有记录 offset 值的分区,则需要调用 KafkaConsumer#updateFetchPositions 方法对这些分区进行更新:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 private void updateFetchPositions (Set<TopicPartition> partitions) fetcher.resetOffsetsIfNeeded(partitions); if (!subscriptions.hasAllFetchPositions(partitions)) { coordinator.refreshCommittedOffsetsIfNeeded(); fetcher.updateFetchPositions(partitions); } }
然后,KafkaConsumer 会调用 Fetcher#fetchedRecords 方法尝试从本地获取每个 topic 分区对应的缓存消息。如果本地缓存不命中,则会继续调用 Fetcher#sendFetches 方法构建并发送 FetchRequest 请求,尝试从集群拉取消息。
在调用 Fetcher#fetchedRecords 方法解析并返回服务端响应的消息之前,消费者会先检测当前是否需要执行分区再分配操作,如果需要则直接返回空的结果,这样在不超时的情况下,方法 KafkaConsumer#pollOnce 会立即被再次调用,从而开始对当前 topic 分区执行再分配,即调用 ConsumerCoordinator#poll 方法。我们会在后面的小节中对分区再分配和自动提交 offset 操作的逻辑展开分析,这里我们先来看一下 ConsumerCoordinator#poll 方法,了解这 2 个步骤的触发过程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 public void poll (long now) this .invokeCompletedOffsetCommitCallbacks(); if (subscriptions.partitionsAutoAssigned() && this .coordinatorUnknown()) { this .ensureCoordinatorReady(); now = time.milliseconds(); } if (this .needRejoin()) { if (subscriptions.hasPatternSubscription()) { client.ensureFreshMetadata(); } this .ensureActiveGroup(); now = time.milliseconds(); } this .pollHeartbeat(now); this .maybeAutoCommitOffsetsAsync(now); }
我们前面介绍了 Kafka 有 3 种订阅模式:AUTO_TOPICS、AUTO_PATTERN,和 USER_ASSIGNED。其中 USER_ASSIGNED 订阅模式是由用户手动指定消费的分区,所以这种模式下不需要执行分区再分配操作对消费者消费的分区进行动态再分配。对于另外 2 种订阅模式来说,如果需要执行分区再分配,则方法首先需要确保与服务端交互的 GroupCoordinator 实例所在 broker 节点是可用的,然后调用 AbstractCoordinator#ensureActiveGroup 方法执行具体的分区再分配操作,我们将在 2.3 小节对这一过程进行深入分析。如果启用了自动 offset 提交策略,上述方法在最后还会调用 ConsumerCoordinator#maybeAutoCommitOffsetsAsync 方法尝试提交当前消费完成的 offset 值,我们将在 2.4 小节对自动提交 offset 的过程展开分析。
当我们使用 AUTO_TOPICS 或 AUTO_PATTERN 模式订阅 Kafka topic 时,我们并不需要考虑当前消费者具体消费哪个分区,Kafka 会依据分区分配策略为消费者分配一个或多个分区进行消费(一个分区至多被一个消费者消费,不允许多个消费者同时消费同一个分区)。但是消费者可能会中途加入,也可能会中途退出,topic 的分区数目也是允许改变的,此时就需要依赖分区再分配机制为注册的消费者重新分配分区。
当一个消费者发送心跳信息时,如果在集群的响应中侦测到 REBALANCE_IN_PROGRESS 错误码,则该消费者会意识到所属 group 正在执行分区再分配操作,于是会停下手头上的工作加入到这一进程中来。分区再分配操作分为 3 个阶段,并且是一个与集群交互联动的过程,这里我们以客户端视角,当消费者检测到需要重新分配分区时会触发执行:
发送 GroupCoordinatorRequest 请求获取目标可用的 GroupCoordinator 实例所在的 broker 节点,如果没有则选择负载最小的节点并尝试建立连接;
向 GroupCoordinator 实例所在节点发送 JoinGroupRequest 请求申请加入目标 group。GroupCoordinator 实例会在既定时间范围内等待消费者的申请加入请求,如果提前检测到已经接收到 group 名下所有消费者的申请,或者等待时间超时,则会返回 JoinGroupResponse 响应,主要目的是告知谁是新的 Group Leader 消费者,以及最终确定的分区分配策略;
Group Leader 依据指定的分区分配策略为当前 group 名下的消费者分配分区,并向目标 GroupCoordinator 实例所在节点发送 SyncGroupRequest 请求以告知最终的分区分配结果。
上述时序图描绘了分区再分配期间客户端与服务端的交互过程。
触发分区再分配操作的场景主要有以下 3 种:
有消费者加入或离开 group,这里的离开可能是主动离开,也可能是宕机、GC 卡顿,或者是取消了对目标 topic 的订阅等。
消费者订阅的 topic 的分区数目发生变化。
消费者 group 对应的 GroupCoordinator 节点发生变更。
在 2.2 小节我们最后简单分析了 ConsumerCoordinator#poll 方法,该方法会调用 ConsumerCoordinator#needRejoin 检测是否需要执行分区再分配,并在需要的情况下予以执行。ConsumerCoordinator 是消费者执行分区再分配操作和 offset 提交的核心类,该类继承自 AbstractCoordinator 抽象类,首先来看一下这两个类的字段定义:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 public abstract class AbstractCoordinator implements Closeable protected final int rebalanceTimeoutMs; private final int sessionTimeoutMs; private final boolean leaveGroupOnClose; private final Heartbeat heartbeat; private HeartbeatThread heartbeatThread = null ; protected final String groupId; protected final ConsumerNetworkClient client; protected final Time time; protected final long retryBackoffMs; private boolean rejoinNeeded = true ; private boolean needsJoinPrepare = true ; private MemberState state = MemberState.UNJOINED; private RequestFuture<ByteBuffer> joinFuture = null ; private Node coordinator = null ; private Generation generation = Generation.NO_GENERATION; private RequestFuture<Void> findCoordinatorFuture = null ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 public final class ConsumerCoordinator extends AbstractCoordinator private final List<PartitionAssignor> assignors; private final Metadata metadata; private final SubscriptionState subscriptions; private final OffsetCommitCallback defaultOffsetCommitCallback; private final boolean autoCommitEnabled; private final int autoCommitIntervalMs; private final ConsumerInterceptors<?, ?> interceptors; private final boolean excludeInternalTopics; private final AtomicInteger pendingAsyncCommits; private final ConcurrentLinkedQueue<OffsetCommitCompletion> completedOffsetCommits; private boolean isLeader = false ; private Set<String> joinedSubscription; private MetadataSnapshot metadataSnapshot; private MetadataSnapshot assignmentSnapshot; private long nextAutoCommitDeadline; }
下面我们开始分析分区再分配机制,首先来看一下判定需要执行分区再分配操作的条件,位于 ConsumerCoordinator#needRejoin 中,实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public boolean needRejoin () if (!subscriptions.partitionsAutoAssigned()) { return false ; } if (assignmentSnapshot != null && !assignmentSnapshot.equals(metadataSnapshot)) { return true ; } if (joinedSubscription != null && !joinedSubscription.equals(subscriptions.subscription())) { return true ; } return super .needRejoin(); }
如果判定需要执行分区再分配操作,消费者接下去会调用 AbstractCoordinator#ensureActiveGroup 方法确认所属 group 对应的目标 GroupCoordinator 实例所在节点是否准备好接收请求,如果对应节点不可用,则会发送 GroupCoordinatorRequest 请求查找负载较小且可用的节点,并与之建立连接。接着会调用 AbstractCoordinator#joinGroupIfNeeded 方法开始执行分区再分配策略,实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 void joinGroupIfNeeded () while (this .needRejoin() || this .rejoinIncomplete()) { this .ensureCoordinatorReady(); if (needsJoinPrepare) { this .onJoinPrepare(generation.generationId, generation.memberId); needsJoinPrepare = false ; } RequestFuture<ByteBuffer> future = this .initiateJoinGroup(); client.poll(future); this .resetJoinGroupFuture(); if (future.succeeded()) { needsJoinPrepare = true ; this .onJoinComplete(generation.generationId, generation.memberId, generation.protocol, future.value()); } else { RuntimeException exception = future.exception(); if (exception instanceof UnknownMemberIdException || exception instanceof RebalanceInProgressException || exception instanceof IllegalGenerationException) { continue ; } else if (!future.isRetriable()) { throw exception; } time.sleep(retryBackoffMs); } } }
在开始执行分区再分配操作之前需要执行一些前期准备工作,这里使用了 needsJoinPrepare 字段进行控制,如果当前正在执行分区再分配,则 needsJoinPrepare 字段会被标记为 false,以防止重复执行。准备工作的逻辑实现位于 ConsumerCoordinator#onJoinPrepare 方法中,主要做了 3 件事情:
如果开启了 offset 自动提交,则同步提交 offset 到集群。
激活注册的 ConsumerRebalanceListener 监听器的 onPartitionsRevoked 方法。
取消当前消费者的 Leader 身份(如果是的话),将其恢复成为一个普通的消费者。
分区再分配操作之前需要提交当前消费者消费完成的 offset,因为当分区再分配完成之后,相应的分区可能会被分配给其它消费者,新的消费者需要依赖于前任消费者提交的 offset 来确定接下去消费的起始位置。所以,为了防止消息的遗漏或重复消费,在开始执行分区再分配之前,需要先提交当前消费者已经完成消费的 offset 值。
ConsumerRebalanceListener 监听器用于监听分区再分配操作,接口定义如下:
1 2 3 4 public interface ConsumerRebalanceListener void onPartitionsRevoked (Collection<TopicPartition> partitions) void onPartitionsAssigned (Collection<TopicPartition> partitions) }
其中 onPartitionsRevoked 方法会在分区再分配操作之前被触发,也就是我们当前分析的位置,而 onPartitionsAssigned 方法则会在分区再分配操作完成之后被触发,调用的位置位于 ConsumerCoordinator#onJoinComplete 方法中,我们后面会对该方法进行分析。
因为接下去要执行分区再分配操作,当操作完成之后会有新的 Group Leader 消费者被选出,如果当前消费者是 Leader 角色,那么此时需要剥夺其 Leader 身份,同时将其 SubscriptionState#groupSubscription 字段中记录的所属 group 名下所有消费者订阅的 topic 集合重置为当前消费者自己订阅的 topic 集合。
完成了前期准备工作之后,消费者将正式开始执行分区再分配,这是一个客户端与服务端交互配合的过程,消费者需要构造并发送 JoinGroupResult 请求到对应的 GroupCoordinator 实例所在节点申请加入目标 group。这一过程位于 AbstractCoordinator#initiateJoinGroup 方法中,该方法的主要工作就是切换当前消费者的状态为 REBALANCING,创建并缓存 JoinGroupRequest 请求,并处理申请加入的结果。如果申请加入成功,则会切换当前消费者的状态为 STABLE,并重启心跳机制(为了避免心跳机制干扰分区再分配,在开始执行分区再分配之前会临时关闭心跳机制);如果申请加入失败,则会切换当前消费者的状态为 UNJOINED。
JoinGroupRequest 请求中包含了当前消费者的 ID,消费者所属 group 的 ID、消费者支持的分区策略、协议类型、以及会话超时时间等信息。构造、发送,以及处理 JoinGroupRequest 请求及其响应的过程位于 AbstractCoordinator#sendJoinGroupRequest 方法中,实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 private RequestFuture<ByteBuffer> sendJoinGroupRequest () if (this .coordinatorUnknown()) { return RequestFuture.coordinatorNotAvailable(); } log.info("(Re-)joining group {}" , groupId); JoinGroupRequest.Builder requestBuilder = new JoinGroupRequest.Builder( groupId, sessionTimeoutMs, generation.memberId, protocolType(), metadata()).setRebalanceTimeout(rebalanceTimeoutMs); log.debug("Sending JoinGroup ({}) to coordinator {}" , requestBuilder, this .coordinator); return client.send(coordinator, requestBuilder).compose(new JoinGroupResponseHandler()); }
消费者通过注册结果处理器 JoinGroupResponseHandler 对请求的响应结果进行处理,如果是正常响应则会执行分区分配操作,核心逻辑实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 synchronized (AbstractCoordinator.this ) { if (state != MemberState.REBALANCING) { future.raise(new UnjoinedGroupException()); } else { generation = new Generation( joinResponse.generationId(), joinResponse.memberId(), joinResponse.groupProtocol()); rejoinNeeded = false ; if (joinResponse.isLeader()) { onJoinLeader(joinResponse) .chain(future); } else { onJoinFollower().chain(future); } } }
在开始重新分配分区之前,消费者会确认当前状态是不是 REBALANCING,前面在发送 JoinGroupRequest 请求之前会将消费者状态变更为 REBALANCING,这里再次确认以防止在请求的过程中消费者的状态发生了变更,例如消费者因某种原理离开了所属的 group,这种情况下不应该再继续执行下去。如果状态未发生变更,那么会依据响应更新本地记录的状态信息(包括年代信息、标识不需要执行分区再分配等),然后依据当前消费者的角色(Leader/Follower)执行相应的逻辑。
对于 Follower 消费者而言,响应 JoinGroupRequest 请求的逻辑只是构造一个包含空的分区分配结果的 SyncGroupRequest 请求,并附带上所属的 group 和自身 ID,以及 group 年代信息,发送给对应的 GroupCoordinator 节点,如果此时所属的 group 已经处于正常运行的状态,则该消费者会拿到分配给自己的分区信息。
如果当前消费者是 Leader 角色,那么需要依据 GroupCoordinator 最终确定的分区分配策略为当前 group 名下所有的消费者分配分区,并发送 SyncGroupRequest 请求向对应的 GroupCoordinator 节点反馈最终的分区分配结果。方法 AbstractCoordinator#onJoinLeader 的实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 private RequestFuture<ByteBuffer> onJoinLeader (JoinGroupResponse joinResponse) try { Map<String, ByteBuffer> groupAssignment = this .performAssignment( joinResponse.leaderId(), joinResponse.groupProtocol(), joinResponse.members()); SyncGroupRequest.Builder requestBuilder = new SyncGroupRequest.Builder(groupId, generation.generationId, generation.memberId, groupAssignment); log.debug("Sending leader SyncGroup for group {} to coordinator {}: {}" , groupId, this .coordinator, requestBuilder); return this .sendSyncGroupRequest(requestBuilder); } catch (RuntimeException e) { return RequestFuture.failure(e); } }
分配分区的具体过程位于 ConsumerCoordinator#performAssignment 方法中,这是一个长长的方法实现,但是逻辑并不复杂,实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 protected Map<String, ByteBuffer> performAssignment (String leaderId, // leader 消费者 ID String assignmentStrategy, // 服务端最终确定的分区分配策略 Map<String, ByteBuffer> allSubscriptions // group 名下所有消费者的 topic 订阅信息 ) PartitionAssignor assignor = this .lookupAssignor(assignmentStrategy); if (assignor == null ) { throw new IllegalStateException("Coordinator selected invalid assignment protocol: " + assignmentStrategy); } Set<String> allSubscribedTopics = new HashSet<>(); Map<String, Subscription> subscriptions = new HashMap<>(); for (Map.Entry<String, ByteBuffer> subscriptionEntry : allSubscriptions.entrySet()) { Subscription subscription = ConsumerProtocol.deserializeSubscription(subscriptionEntry.getValue()); subscriptions.put(subscriptionEntry.getKey(), subscription); allSubscribedTopics.addAll(subscription.topics()); } this .subscriptions.groupSubscribe(allSubscribedTopics); metadata.setTopics(this .subscriptions.groupSubscription()); client.ensureFreshMetadata(); isLeader = true ; log.debug("Performing assignment for group {} using strategy {} with subscriptions {}" , groupId, assignor.name(), subscriptions); Map<String, Assignment> assignment = assignor.assign(metadata.fetch(), subscriptions); Set<String> assignedTopics = new HashSet<>(); for (Assignment assigned : assignment.values()) { for (TopicPartition tp : assigned.partitions()) assignedTopics.add(tp.topic()); } if (!assignedTopics.containsAll(allSubscribedTopics)) { Set<String> notAssignedTopics = new HashSet<>(allSubscribedTopics); notAssignedTopics.removeAll(assignedTopics); log.warn("The following subscribed topics are not assigned to any members in the group {} : {} " , groupId, notAssignedTopics); } if (!allSubscribedTopics.containsAll(assignedTopics)) { Set<String> newlyAddedTopics = new HashSet<>(assignedTopics); newlyAddedTopics.removeAll(allSubscribedTopics); log.info("The following not-subscribed topics are assigned to group {}, and their metadata will be fetched from the brokers : {}" , groupId, newlyAddedTopics); allSubscribedTopics.addAll(assignedTopics); this .subscriptions.groupSubscribe(allSubscribedTopics); metadata.setTopics(this .subscriptions.groupSubscription()); client.ensureFreshMetadata(); } assignmentSnapshot = metadataSnapshot; log.debug("Finished assignment for group {}: {}" , groupId, assignment); Map<String, ByteBuffer> groupAssignment = new HashMap<>(); for (Map.Entry<String, Assignment> assignmentEntry : assignment.entrySet()) { ByteBuffer buffer = ConsumerProtocol.serializeAssignment(assignmentEntry.getValue()); groupAssignment.put(assignmentEntry.getKey(), buffer); } return groupAssignment; }
整个分区分配的执行流程可以概括为:
校验服务端确定的最终分区策略,获取对应的分区分配器 PartitionAssignor 对象;
反序列化解析并封装服务端返回的当前 group 名下所有消费者的 topic 订阅信息;
更新消费者本地缓存的状态信息,包括 group 名下所有消费者订阅的 topic 集合,Leader 角色自己订阅的 topic 集合等;
检查是否需要更新本地集群元数据信息,如果需要则立即执行更新;
依据具体的分区分配策略执行分区分配操作;
校验分区分配结果,如果 group 已经订阅的一些 topic 并未被分配,则记录到日志;
校验分配结果,如果分配了一些并未订阅的 topic,则将其加入到 group 集合中,并更新本地集群元数据信息;
序列化封装并返回分区分配结果,后续需要反馈给集群。
Kafka 目前主流的分区分配策略分为 2 种(默认是 range,可以通过 partition.assignment.strategy 参数指定):
range :在保证均衡的前提下,将连续的分区分配给消费者,对应的实现是 RangeAssignor。round-robin :在保证均衡的前提下,轮询分配,对应的实现是 RoundRobinAssignor。
在 0.11.0.0 版本引入了一种新的分区分配策略 StickyAssignor,相对于上面两种分区分配策略的优势在于能够在保证分区均衡的前提下尽量保持原有的分区分配结果,从而避免许多冗余的分区分配操作,减少分区再分配的执行时间。不过据反映 StickyAssignor 目前还存在一些小 bug,所以在你的应用中具体是否采用还需要斟酌。
说到这里我们插点题外话,聊聊分区再分配机制的缺点。我们知道分区再分配机制设计的出发点是好的,也确实解决了实际面临的一些问题,但是缺点在于执行过程效率太低,究其根本可以概括为以下 2 方面的原因:
在执行分区再分配过程中,对应 group 名下的所有消费者都需要暂停手头上的工作加入到分区再分配过程中来,外在的表现就是整个 group 在此期间不消费新的消息,会出现一段时间的消息堆积,有点 Stop The World 的意思。
基于 RangeAssignor 或 RoundRobinAssignor 分区分配策略会对 group 名下所有消费者的分区分配方案重新洗牌,实际上较好的策略是尽量复用原有的分区分配结果,并在此基础上进行微调,从而最大利用原有的状态信息,避免一些冗余的工作量。
实际中因为订阅的 topic 数目发生变更,或者 topic 分区数目的变化导致触发的分区再分配操作我们无法避免,但是此类情况发生的概率较小,大部分的分区再分配都是由于消费者上下线导致的,而且是被 Kafka 误判为下线。Kafka 基于心跳机制来对具体的一个消费者进行判活,如果对应的参数设置不当会极大增加误判率,所以在这一块的参数配置上需要仔细斟酌。
继续接着分析分区再分配机制的实现,步骤 5 会依据具体的分区分配策略对分区执行分配操作,即执行 PartitionAssignor#assign 方法,我们已经知晓了每种分配算法的思想,具体分配细节这里不再深入。
完成了分配分区之后,消费者(不管是 Leader,还是 Follower)会构建 SyncGroupRequest 请求,将分区分配结果信息发送给对应的 GroupCoordinator 实例所在节点,并最终保存在服务端。如果请求异常,则会调用 AbstractCoordinator#requestRejoin 方法标记需要再次执行分区再分配操作。
下面继续回到 AbstractCoordinator#joinGroupIfNeeded 方法,如果分区分配操作失败,则消费者会依据异常类型决定是否继续重试。如果分区分配成功,则接下来需要对本地记录的相关信息重新初始化,因为分配给当前消费者的分区很可能已经变化,消费者需要知晓上一任消费者对当前分区的消费情况,从而找到合适的 offset 位置继续消费,相关实现位于 ConsumerCoordinator#onJoinComplete 方法中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 protected void onJoinComplete (int generation, String memberId, String assignmentStrategy, ByteBuffer assignmentBuffer) if (!isLeader) { assignmentSnapshot = null ; } PartitionAssignor assignor = this .lookupAssignor(assignmentStrategy); if (assignor == null ) { throw new IllegalStateException("Coordinator selected invalid assignment protocol: " + assignmentStrategy); } Assignment assignment = ConsumerProtocol.deserializeAssignment(assignmentBuffer); subscriptions.needRefreshCommits(); subscriptions.assignFromSubscribed(assignment.partitions()); Set<String> addedTopics = new HashSet<>(); for (TopicPartition tp : subscriptions.assignedPartitions()) { if (!joinedSubscription.contains(tp.topic())) { addedTopics.add(tp.topic()); } } if (!addedTopics.isEmpty()) { Set<String> newSubscription = new HashSet<>(subscriptions.subscription()); Set<String> newJoinedSubscription = new HashSet<>(joinedSubscription); newSubscription.addAll(addedTopics); newJoinedSubscription.addAll(addedTopics); subscriptions.subscribeFromPattern(newSubscription); joinedSubscription = newJoinedSubscription; } metadata.setTopics(subscriptions.groupSubscription()); client.ensureFreshMetadata(); assignor.onAssignment(assignment); nextAutoCommitDeadline = time.milliseconds() + autoCommitIntervalMs; ConsumerRebalanceListener listener = subscriptions.listener(); log.info("Setting newly assigned partitions {} for group {}" , subscriptions.assignedPartitions(), groupId); try { Set<TopicPartition> assigned = new HashSet<>(subscriptions.assignedPartitions()); listener.onPartitionsAssigned(assigned); } catch (WakeupException | InterruptException e) { throw e; } catch (Exception e) { log.error("User provided listener {} for group {} failed on partition assignment" , listener.getClass().getName(), groupId, e); } }
上述方法主要做了以下 4 件事情:
标记需要重新从集群获取最近一次提交的 offset 值。
重置本地记录的每个分区的消费状态,并更新本地记录的 topic 订阅信息。
条件性更新本地记录的集群元数据信息。
激活 ConsumerRebalanceListener 监听器的 onPartitionsAssigned 方法。
前面我们介绍了 ConsumerRebalanceListener 接口的定义,在分区再分配操作执行之前会调用 ConsumerRebalanceListener#onPartitionsRevoked 方法,而另外一个方法 ConsumerRebalanceListener#onPartitionsAssigned 的调用时机则是位于这里。
提交已经消费完成的消息对应的 offset 是保证消息不重复消费和遗漏消费的最重要的措施。这里提交的 offset 是下一条待消费消息的 offset,而非当前已经消费的最后一条消息的 offset。Kafka 默认会按照指定时间间隔自动提交消费者消费完成的 offset 值,同时也允许开发者手动控制 offset 的提交时机。提交操作分为同步(阻塞)和异步(非阻塞)两种,Kafka 为手动提交分别提供了对应 KafkaConsumer#commitSync 和 KafkaConsumer#commitAsync 方法实现,这些方法都存在多个重载版本,相应的实现均位于 ConsumerCoordinator 类中。
ConsumerCoordinator 类提供了多个提交 offset 的方法,区分同步和异步,这些方法之间的调用关系如下所示:
1 2 + maybeAutoCommitOffsetsSync | ---- + commitOffsetsSync
1 2 3 4 + maybeAutoCommitOffsetsNow / maybeAutoCommitOffsetsAsync | ---- + doAutoCommitOffsetsAsync | ---- | ---- + commitOffsetsAsync | ---- | ---- | ---- + doCommitOffsetsAsync
整个方法调用链路按照同步和异步提交方式分为两条独立的路线,自动提交和手动提交在底层实现上其实是复用的,下面的篇幅中我们分别分析同步提交和异步提交的具体实现细节。
我们从 ConsumerCoordinator#maybeAutoCommitOffsetsSync 方法切入,该方法的调用时机有两个地方:
执行分区再分配操作的准备阶段(ConsumerCoordinator#onJoinPrepare 方法)。
关闭消费者的时候(ConsumerCoordinator#close 方法,KafkaConsumer#close 方法在执行时会调用该方法)。
前面曾提到过,当分区再分配操作完成之后,分区与消费者之间的订阅关系可能会发生变化,而 Kafka 又依赖于消费者自己去记录分区的消费状态,所以在执行分区再分配操作之前需要让每个消费者将自己维护的分区消费状态信息上报给集群,这样在完成分区重新分配之后,消费者可以通过请求就集群以知晓新分配的分区的消费 offset 位置,消费者关闭的过程本质上也是如此。这些场景下提交 offset 的过程必须是同步的,否则存在丢失消费状态的可能,最终将导致消息被重复消费。
方法 ConsumerCoordinator#maybeAutoCommitOffsetsSync 的实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 private void maybeAutoCommitOffsetsSync (long timeoutMs) if (autoCommitEnabled) { Map<TopicPartition, OffsetAndMetadata> allConsumedOffsets = subscriptions.allConsumed(); try { log.debug("Sending synchronous auto-commit of offsets {} for group {}" , allConsumedOffsets, groupId); if (!this .commitOffsetsSync(allConsumedOffsets, timeoutMs)) { log.debug("Auto-commit of offsets {} for group {} timed out before completion" , allConsumedOffsets, groupId); } } } }
如果允许自动提交 offset,则上述方法首先会从本地获取当前消费者被分配的分区的消费状态,然后调用 ConsumerCoordinator#commitOffsetsSync 方法向集群提交 offset 值,方法 KafkaConsumer#commitSync 本质上也是调用了该方法实现对 offset 的提交操作。方法 ConsumerCoordinator#commitOffsetsSync 的实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 public boolean commitOffsetsSync (Map<TopicPartition, OffsetAndMetadata> offsets, long timeoutMs) this .invokeCompletedOffsetCommitCallbacks(); if (offsets.isEmpty()) { return true ; } long now = time.milliseconds(); long startMs = now; long remainingMs = timeoutMs; do { if (this .coordinatorUnknown()) { if (!this .ensureCoordinatorReady(now, remainingMs)) { return false ; } remainingMs = timeoutMs - (time.milliseconds() - startMs); } RequestFuture<Void> future = this .sendOffsetCommitRequest(offsets); client.poll(future, remainingMs); if (future.succeeded()) { if (interceptors != null ) { interceptors.onCommit(offsets); } return true ; } if (!future.isRetriable()) { throw future.exception(); } time.sleep(retryBackoffMs); now = time.milliseconds(); remainingMs = timeoutMs - (now - startMs); } while (remainingMs > 0 ); return false ; }
同步 offset 提交的执行流程可以概括为:
触发注册的监听 offset 提交完成的回调方法;
校验待提交的 offset 数据是否为空,如果为空则直接返回;
校验目标 GroupCoordinator 实例所在节点是否可用,如果不可用则尝试寻找负载最小且可用的节点;
创建并发送提交 offset 的 OffsetCommitRequest 请求;
处理请求的响应结果。
所有的监听 offset 提交操作的 OffsetCommitCallback 都会被封装成 OffsetCommitCompletion 对象,记录到 ConsumerCoordinator#completedOffsetCommits 字段中,并在每次提交 offset 时触发调用。下面来看一下创建并发送 OffsetCommitRequest 请求的逻辑,实现位于 ConsumerCoordinator#sendOffsetCommitRequest 方法中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 private RequestFuture<Void> sendOffsetCommitRequest (final Map<TopicPartition, OffsetAndMetadata> offsets) if (offsets.isEmpty()) { return RequestFuture.voidSuccess(); } Node coordinator = this .coordinator(); if (coordinator == null ) { return RequestFuture.coordinatorNotAvailable(); } Map<TopicPartition, OffsetCommitRequest.PartitionData> offsetData = new HashMap<>(offsets.size()); for (Map.Entry<TopicPartition, OffsetAndMetadata> entry : offsets.entrySet()) { OffsetAndMetadata offsetAndMetadata = entry.getValue(); if (offsetAndMetadata.offset() < 0 ) { return RequestFuture.failure(new IllegalArgumentException("Invalid offset: " + offsetAndMetadata.offset())); } offsetData.put(entry.getKey(), new OffsetCommitRequest.PartitionData(offsetAndMetadata.offset(), offsetAndMetadata.metadata())); } final Generation generation; if (subscriptions.partitionsAutoAssigned()) { generation = this .generation(); } else { generation = Generation.NO_GENERATION; } if (generation == null ) { return RequestFuture.failure(new CommitFailedException()); } OffsetCommitRequest.Builder builder = new OffsetCommitRequest.Builder(groupId, offsetData) .setGenerationId(generation.generationId) .setMemberId(generation.memberId) .setRetentionTime(OffsetCommitRequest.DEFAULT_RETENTION_TIME); log.trace("Sending OffsetCommit request with {} to coordinator {} for group {}" , offsets, coordinator, groupId); return client.send(coordinator, builder).compose(new OffsetCommitResponseHandler(offsets)); }
上述方法的执行流程如下:
校验待发送的请求数据是否为空,如果为空则直接返回成功;
获取目标 GroupCoordinator 实例所在 broker 节点,并校验其可用性;
封装每个目标分区的待提交 offset 数据;
获取并校验当前 group 的年代信息,防止提交一些已经离开 group 的消费者的 offset 数据;
创建并缓存 OffsetCommitRequest 请求,同时注册响应结果处理器。
整体流程都比较简单和直观,集群 GroupCoordinator 实例在收到 OffsetCommitRequest 请求之后,会依据请求指定的版本号决定将 offset 消费信息记录到 ZK 还是最新实现的 offset topic,我们将在后面分析 GroupCoordinator 组件的篇章中针对 OffsetCommitRequest 请求的处理过程进行深入分析。下面来看一下对于响应结果的处理过程,实现位于 OffsetCommitResponseHandler#handle 方法中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 public void handle (OffsetCommitResponse commitResponse, RequestFuture<Void> future) sensors.commitLatency.record(response.requestLatencyMs()); Set<String> unauthorizedTopics = new HashSet<>(); for (Map.Entry<TopicPartition, Short> entry : commitResponse.responseData().entrySet()) { TopicPartition tp = entry.getKey(); OffsetAndMetadata offsetAndMetadata = offsets.get(tp); long offset = offsetAndMetadata.offset(); Errors error = Errors.forCode(entry.getValue()); if (error == Errors.NONE) { log.debug("Group {} committed offset {} for partition {}" , groupId, offset, tp); if (subscriptions.isAssigned(tp)) { subscriptions.committed(tp, offsetAndMetadata); } } } if (!unauthorizedTopics.isEmpty()) { log.error("Not authorized to commit to topics {} for group {}" , unauthorizedTopics, groupId); future.raise(new TopicAuthorizationException(unauthorizedTopics)); } else { future.complete(null ); } }
这里主要看一下对于正常响应的处理过程,一个消费者可能同时消费多个 topic 分区,前面我们已经说过对于每个 topic 分区的消费状态都是独立维护和提交的,所以对于响应的处理也需要针对每个 topic 分区进行单独处理。如果是正常响应,方法首先会确认对应 topic 分区是否分配给当前消费者,如果是的话则会更新对应的分区消费状态的 TopicPartitionState#committed 字段,本质上也就是将 TopicPartitionState#position 字段记录的消费 offset 值封装成 OffsetAndMetadata 对象进行赋值。
下面继续看一下异步 offset 提交的过程,我们从 ConsumerCoordinator#maybeAutoCommitOffsetsAsync 方法切入。前面我们在分析 ConsumerCoordinator#poll 方法时曾提到了对于该方法的调用,方法的实现比较简单(如下),即判断是否启用了自动提交,如果启用了的话则首先判断对应的 GroupCoordinator 实例所在节点是否可用,如果不可用则修改下一次自动提交的时间戳,延迟到下一次执行,如果目标 GroupCoordinator 节点是可用的,同时自动提交的时间已到,则执行异步提交操作。
1 2 3 4 5 6 7 8 9 10 11 12 private void maybeAutoCommitOffsetsAsync (long now) if (autoCommitEnabled) { if (this .coordinatorUnknown()) { this .nextAutoCommitDeadline = now + retryBackoffMs; } else if (now >= nextAutoCommitDeadline) { this .nextAutoCommitDeadline = now + autoCommitIntervalMs; this .doAutoCommitOffsetsAsync(); } } }
其中,方法 ConsumerCoordinator#doAutoCommitOffsetsAsync 除了在这里被调用之外,也会在 ConsumerCoordinator#maybeAutoCommitOffsetsNow 方法中被调用,用于立即发起一次异步提交 offset 请求,实现比较简单。方法 ConsumerCoordinator#doAutoCommitOffsetsAsync 的实现也比较简单,核心逻辑就是获取当前消费者消费的所有 topic 分区对应的消费状态信息,然后调用 ConsumerCoordinator#commitOffsetsAsync 方法执行异步提交操作。该方法首先会触发注册的监听 offset 提交完成的监听器,然后判断目标 GroupCoordinator 实例所在节点是否可用。如果可用则继续执行异步提交操作,如果不可用则会尝试寻找可用且负载最小的节点,并在找到的前提下继续执行异步提交,否则返回异常。
执行异步提交的核心实现位于 ConsumerCoordinator#doCommitOffsetsAsync 方法中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 private void doCommitOffsetsAsync (final Map<TopicPartition, OffsetAndMetadata> offsets, final OffsetCommitCallback callback) subscriptions.needRefreshCommits(); RequestFuture<Void> future = this .sendOffsetCommitRequest(offsets); final OffsetCommitCallback cb = callback == null ? defaultOffsetCommitCallback : callback; future.addListener(new RequestFutureListener<Void>() { @Override public void onSuccess (Void value) if (interceptors != null ) { interceptors.onCommit(offsets); } completedOffsetCommits.add(new OffsetCommitCompletion(cb, offsets, null )); } @Override public void onFailure (RuntimeException e) Exception commitException = e; if (e instanceof RetriableException) { commitException = new RetriableCommitFailedException(e); } completedOffsetCommits.add(new OffsetCommitCompletion(cb, offsets, commitException)); } }); }
执行提交 OffsetCommitRequest 请求之前,方法首先会标记需要从 GroupCoordinator 实例所在节点获取最近提交的 offset 值,这里的标记主要用于通知那些本地未有效记录分区消费状态的消费者。然后构造并缓存 OffsetCommitRequest 请求对象,等待下次 poll 操作时一并发送,方法 ConsumerCoordinator#sendOffsetCommitRequest 的执行逻辑在前面已经分析过。
异步发送和同步发送主要的区别在于是否立即调用 ConsumerNetworkClient#poll 方法阻塞发送请求,并处理响应结果。前面在介绍同步提交(ConsumerCoordinator#commitOffsetsSync 方法)时可以看到在构建完 OffsetCommitRequest 请求之后会立即执行 poll 方法,而在异步提交时,构建完 OffsetCommitRequest 请求之后并不会立即发送请求,而是会等到下一次执行 poll 方法时一并发送,并通过回调的方式处理响应结果。
本文我们介绍了 java 版本的 KafkaConsumer 的使用,并深入分析了相关设计和实现,了解一个 group 名下的所有消费者区分 Leader 和 Follower 角色,其中 Leader 角色除了肩负普通消费者的职责外,还需要负责管理整个 group 的运行状态。此外,消费者在拉取消息时的预取策略虽然在设计上很简单,却很好的利用了消息拉取和消费这两者之间能够并行执行的特点,极大提升了消费者的运行性能。而分区再分配机制则为 Kafka 提供了良好的扩展性,保证在 topic 分区数据发生变化,以及消费者上下线时能够不停服,继续正常对外提供服务。
到此为止,关于 Kafka SDK 的相关实现已经基本介绍完了,从下一篇开始我们将转战服务端,分析 Kafka 集群各个组件的设计与实现。